WebKit で使われている JIT 周りについて調べたのでメモ。このあたりの知識全然ないまま手探りでリソースを探して解釈した結果を書いているので、間違っていたらご指摘ください。
JSC の execution engine は次の4つの最適化レベルがある。これらは実行時に使い分けられる。
- LLInt
- Baseline JIT
- DFG JIT
- FTL JIT
ref : https://webkit.org/blog/6411/javascriptcore-csi-a-crash-site-investigation-story/#Isolate
LLInt
うっかり Lint と読んでしまいそうになるが、Low Level Interpreter の略。
これは bytecode を実行するもので、ソースは https://github.com/adobe/webkit/blob/master/Source/JavaScriptCore/llint/LowLevelInterpreter.cpp 。ほとんど最適化されない。
Baseline JIT
これのソースは https://github.com/WebKit/webkit/blob/master/Source/JavaScriptCore/jit/JIT.cpp っぽい。
LLInt よりはマシな最適化をするが、高度なことはしないらしい。
次のようなコメントがあった。
// ... When the LLInt determines it wants to
// do OSR entry into the baseline JIT in a loop, it will pass in the bytecode offset it
// was executing at when it kicked off our compilation.
OSR を知らないのだが、on-stack replacement の略でループ内の最適化のことを指すらしい。
なんのこっちゃという気持ちだが、要は実行中に最適化されていないコードから JIT コンパイル済みコードに切り替えるようなことを言う。
で、これがいつ使われるかというと https://webkit.org/blog/3362/introducing-the-webkit-ftl-jit/ に書いてある。
The first execution of any function always starts in the interpreter tier. As soon as any statement in the function executes more than 100 times, or the function is called more than 6 times (whichever comes first), execution is diverted into code compiled by the Baseline JIT.
100 回以上実行されるステートメントが存在したり、関数自体が6回以上呼ばれると、LLInt から Baseline JIT に処理が渡るようだ。
この挙動を確認してみる。
JIT のデバッグをするために環境変数 JSC_dumpDisassembly を true にする。
(lldb) env JSC_dumpDisassembly=true
(lldb) r
There is a running process, kill it and restart?: [Y/n] Y
Process 79453 exited with status = 9 (0x00000009)
Process 19212 launched: 'WebKit/webkit/WebKitBuild/Debug/bin/jsc' (x86_64)
Generated JIT code for internal Call trampoline:
Code at [0x5c9f72a01000, 0x5c9f72a010a0):
0x5c9f72a01000: push %rbp
0x5c9f72a01001: mov %rsp, %rbp
0x5c9f72a01004: mov $0x0, 0x10(%rbp)
0x5c9f72a0100c: mov $0x106d11518, %r11
0x5c9f72a01016: mov %rbp, (%r11)
JSC を再実行した時点でダラダラとデバッグログが出てくる。
次のような loop 関数を用意し、3回、100回とそれぞれ呼んでみると、たしかに途中で Baseline JIT によって生成されたコードが出てくることが確認できた。
>>> function loop(n) {
... for (let i = 0; i < 10; i++) {
... i*2;
... }
... }
>>> for(let j=0; j<3; j++) loop(j)
Generated JIT code for LLInt function for call prologue thunk:
Code at [0x226c9e601840, 0x226c9e601860):
0x226c9e601840: mov $0x10126a56e, %rax
0x226c9e60184a: jmp *%rax
0x226c9e60184c: int3
>>> for(let j=0; j<100; j++) loop(j)
...
Generated Baseline JIT code for loop#ETqdOY:[0x108a50000->0x108afce70, BaselineFunctionCall, 33], instruction count = 33
Source: function loop(n) { for (let i = 0; i < 10; i++) { i*2; } }
Code at [0x3a45e98008a0, 0x3a45e9801000):
0x3a45e98008a0: push %rbp
0x3a45e98008a1: mov %rsp, %rbp
DFG JIT
Baseline JIT の次は DFG JIT が呼ばれる。DFG は Data Flow Graph の略。
これも LLInt と同じように特定の回数関数が呼ばれると Baseline JIT から切り替わる仕組みになっている。
こちらはステートメントが 1000 回、もしくは、関数が66回呼び出されると切り替わる。
コードはこれかな https://github.com/WebKit/webkit/blob/master/Source/JavaScriptCore/dfg/DFGJITCompiler.cpp
DFG JIT Pipeline を見ると、DFG CPS form とやらに変換するところから始まるらしい。
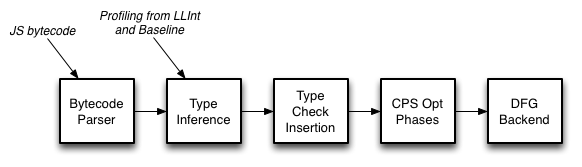
CPS というのは continuation-passing style の略で、日本語だと継続渡し方式などと呼ぶらしい。
いわゆるこういうコードで return せずに次の関数を呼び出すスタイル(これって CPS って言うんですね…完全に無知)。
function cps(x, done){
done(x * x);
}
で、こういうコードになったあと、何が行われるかというと型推測やチェックが行われる。
function foo(a, b) { return a + b + 42; }
こういうコードを見たとき、引数が文字列なのか数値なのか分からないが、繰り返し実行されている間 LLInt や Baseline JIT でプロファイリングが行われており、最終的にそのプロファイリング結果を元に型を推測することで valueOf() のような処理を省略しているらしい。
これも先と同じような手順で実験すると呼ばれることが確認できる。
...
Generated JIT code for DFG OSR exit generation thunk:
Code at [0x44eb45c01940, 0x44eb45c01bc0):
0x44eb45c01940: push %rsi
0x44eb45c01941: mov $0x106cae878, %rsi
...
FTL JIT
FTL は Faster Than Light の略。これは以前バックエンドが LLVM だったが、今は Bare Bones Backend(B3) というものに置き換わっているらしい。
DFG の代替となるもので、DFG では CPS 形式に変換するのに対して、SSA(静的単一代入)形式に変換するらしい。
C like な最適化を行うと書かれているが、計算結果の即値代入みたいな感じなのかな。
この優位性は https://webkit.org/blog/3362/introducing-the-webkit-ftl-jit/ の「Architecting a Fourth Tier JIT」あたりに書かれている。
こちらも関数を呼び出す回数を増やすと出現する。
>>> for(let j=0; j<10000; j++) loop(j)
...
Generated FTLMode code for loop#ETqdOY:[0x108a50460->0x108a50000->0x108afce70, FTLFunctionCall, 33], instruction count = 33:
BB#0: ; frequency = 1.000000
0x44eb45c03360: push %rbp
0x44eb45c03361: mov %rsp, %rbp
0x44eb45c03364: lea -0x30(%rbp), %rsp
Int64 @16 = Const64(4439999584)
...
JIT を利用した攻撃と防御方法
JIT で型チェックが行われずに、過去のプロファイルから推測されたものを信頼する動作を利用して、Type Confusion を引き起こすことができたりするらしい。
例えば [1.1, 1.2, 1.3, 1.4] という double の配列があり、その先頭要素を返すという処理があるとする。JIT によって最適化されて型チェックなどをスキップされている場合に、例えば {} に置き換えると double のまま {} のポインタを返すことになる。
他にも obj.x へのアクセスが最適化されている状態で、 obj.x が削除された場合にも同じことが言える。
では、これをどう防ぐかというと、このような副作用を持つ関数に対しては、潜在的に危険であるという印をつけるために clobberWorld() を呼び出している。
例えば Array.push や String.valueOf などで呼ばれていることが dfg/DFGAbstractInterpreterInlines.h で確認できる。
- https://github.com/WebKit/webkit/blob/master/Source/JavaScriptCore/dfg/DFGAbstractInterpreterInlines.h#L2331
- https://github.com/WebKit/webkit/blob/master/Source/JavaScriptCore/dfg/DFGAbstractInterpreterInlines.h#L1322
...
case StringValueOf: {
clobberWorld();
setTypeForNode(node, SpecString);
break;
}
...
case ArrayPush:
clobberWorld();
setNonCellTypeForNode(node, SpecBytecodeNumber);
break;
clobberWorld() の実装は https://github.com/WebKit/webkit/blob/6b0ee98f241d4912bd4e7ffcacb0cf19df8ece72/Source/JavaScriptCore/dfg/DFGAbstractInterpreterInlines.h#L3877 で、 clobberStructures() を呼び出している。
clobberStructures() の実装は https://github.com/WebKit/webkit/blob/6b0ee98f241d4912bd4e7ffcacb0cf19df8ece72/Source/JavaScriptCore/dfg/DFGAbstractInterpreterInlines.h#L3918 にある。
template<typename AbstractStateType>
void AbstractInterpreter<AbstractStateType>::clobberStructures()
{
m_state.clobberStructures();
m_state.mergeClobberState(AbstractInterpreterClobberState::ClobberedStructures);
m_state.setStructureClobberState(StructuresAreClobbered);
}
StructuresAreClobbered をセットすることで、そのオブジェクトは汚染されているかもしれないという状態にするのかな。
References
- https://webkit.org/blog/3362/introducing-the-webkit-ftl-jit/
- https://webkit.org/blog/9329/a-new-bytecode-format-for-javascriptcore/
- https://www.infoq.com/jp/news/2014/05/safari-webkit-javascript-llvm/
- https://webkit.org/blog/6411/javascriptcore-csi-a-crash-site-investigation-story
- https://github.com/vngkv123/aSiagaming/tree/master/Safari-JSC-RealWorldCTF
- https://docs.ioin.in/writeup/www.auxy.xyz/_tutorial_Webkit_Exp_Tutorial_/index.html
- https://www.youtube.com/watch?v=45wMEIIPsPA