環境
$ uname -a
Linux ubuntu-bionic 4.15.0-62-generic #69-Ubuntu SMP Wed Sep 4 20:55:53 UTC 2019 x86_64 x86_64 x86_64 GNU/Linux
TCPソケットの状態遷移図
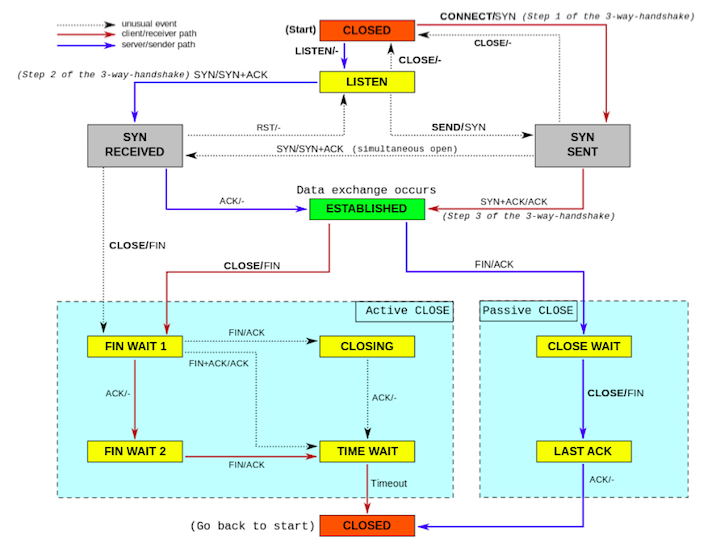
Ref : https://meetup-jp.toast.com/1516
クライアントは SYN を送った場合に SYN SENT 状態になる。
サーバーはこれを受け取った場合に SYN RECV となり、ACK を返して ESTABLISHED となる。
ss で確認する
nc で LISTEN する。
$ nc -lvp 12345
ss で確認すると LISTEN 状態になっている。
$ ss -tan | grep 12345
LISTEN 0 1 0.0.0.0:12345 0.0.0.0:*
接続すると ESTABLISHED 状態になったソケットを確認できる。
LISTEN 0 1 0.0.0.0:12345 0.0.0.0:*
ESTAB 0 0 127.0.0.1:12345 127.0.0.1:51978
systemtap で確認してみる
nc で作成されたソケットがどのように変化するのか、簡易な SystemTap スクリプトで確認する。
%{
#include <net/tcp.h>
#include <linux/skbuff.h>
#include <net/inet_connection_sock.h>
#include <net/inet_timewait_sock.h>
#include <uapi/linux/tcp.h>
%}
function show_state:long(sk:long)
%{
struct sock *sk = (struct sock *)STAP_ARG_sk;
struct inet_sock *inet;
inet = inet_sk(sk);
if (inet->inet_num == 12345) {
switch (sk->sk_state) {
case TCP_LISTEN:
STAP_PRINTF("TCP_LISTEN\n");
break;
case TCP_SYN_SENT:
STAP_PRINTF("TCP_SYN_SENT\n");
break;
case TCP_NEW_SYN_RECV:
STAP_PRINTF("TCP_NEW_SYN_RECV\n");
break;
case TCP_SYN_RECV:
STAP_PRINTF("TCP_SYN_RECV\n");
break;
case TCP_ESTABLISHED:
STAP_PRINTF("TCP_ESTABLISHED\n");
break;
}
}
%}
probe kernel.function("tcp_v4_do_rcv")
{
if (execname() == "nc")
printf ("%s -> %s\n", thread_indent(1), probefunc())
show_state($sk);
}
probe kernel.function("tcp_v4_do_rcv").return
{
if (execname() == "nc")
printf ("%s <- %s\n", thread_indent(-1), probefunc())
show_state($sk);
}
probe kernel.function("tcp_rcv_state_process")
{
if (execname() == "nc")
printf("%s -> %s\n", thread_indent(-1), probefunc())
show_state($sk);
}
$ sudo stap -g -v trace.stp
...
Pass 5: starting run.
0 nc(7522): -> tcp_v4_do_rcv
TCP_LISTEN
9 nc(7522): -> tcp_rcv_state_process
TCP_LISTEN
0 nc(7522): <- tcp_v4_rcv
TCP_LISTEN
4 nc(7522): -> tcp_v4_do_rcv
0 nc(7522): -> tcp_rcv_state_process
15 nc(7522): -> tcp_rcv_state_process
TCP_SYN_RECV
49 nc(7522): <- __release_sock
3972825 nc(7522): -> tcp_v4_do_rcv
TCP_ESTABLISHED
...
サーバー側はたしかに LISTEN → SYN_RECV → ESTABLISHED と変化していることが確認できた。
カーネルを読んで処理を追いかける
まずは listen(2) が呼び出される箇所から確認していく。
SYSCALL_DEFINE2(listen, int, fd, int, backlog)
{
struct socket *sock;
int err, fput_needed;
int somaxconn;
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (sock) {
somaxconn = sock_net(sock->sk)->core.sysctl_somaxconn;
if ((unsigned int)backlog > somaxconn)
backlog = somaxconn;
err = security_socket_listen(sock, backlog);
if (!err)
err = sock->ops->listen(sock, backlog);
fput_light(sock->file, fput_needed);
}
return err;
}
net.ipv4.tcp_max_syn_backlog が net.core.somaxconn の値より大きい場合は net.core.somaxconn の値を優先するのだが、その処理はこのあたりっぽい。
somaxconn = sock_net(sock->sk)->core.sysctl_somaxconn;
if ((unsigned int)backlog > somaxconn)
backlog = somaxconn;
sock->ops->listen(sock, backlog); で inet_listen() が呼ばれる。
int inet_listen(struct socket *sock, int backlog)
{
struct sock *sk = sock->sk;
unsigned char old_state;
int err, tcp_fastopen;
...
/* Really, if the socket is already in listen state
* we can only allow the backlog to be adjusted.
*/
if (old_state != TCP_LISTEN) {
/* Enable TFO w/o requiring TCP_FASTOPEN socket option.
* Note that only TCP sockets (SOCK_STREAM) will reach here.
* Also fastopen backlog may already been set via the option
* because the socket was in TCP_LISTEN state previously but
* was shutdown() rather than close().
*/
tcp_fastopen = sock_net(sk)->ipv4.sysctl_tcp_fastopen;
if ((tcp_fastopen & TFO_SERVER_WO_SOCKOPT1) &&
(tcp_fastopen & TFO_SERVER_ENABLE) &&
!inet_csk(sk)->icsk_accept_queue.fastopenq.max_qlen) {
fastopen_queue_tune(sk, backlog);
tcp_fastopen_init_key_once(sock_net(sk));
}
err = inet_csk_listen_start(sk, backlog);
if (err)
goto out;
}
sk->sk_max_ack_backlog = backlog;
err = 0;
...
さらに inet_csk_listen_start() が呼ばれている。
int inet_csk_listen_start(struct sock *sk, int backlog)
{
struct inet_connection_sock *icsk = inet_csk(sk);
struct inet_sock *inet = inet_sk(sk);
int err = -EADDRINUSE;
reqsk_queue_alloc(&icsk->icsk_accept_queue);
sk->sk_max_ack_backlog = backlog;
sk->sk_ack_backlog = 0;
inet_csk_delack_init(sk);
/* There is race window here: we announce ourselves listening,
* but this transition is still not validated by get_port().
* It is OK, because this socket enters to hash table only
* after validation is complete.
*/
sk_state_store(sk, TCP_LISTEN);
if (!sk->sk_prot->get_port(sk, inet->inet_num)) {
inet->inet_sport = htons(inet->inet_num);
sk_dst_reset(sk);
err = sk->sk_prot->hash(sk);
if (likely(!err))
return 0;
}
sk->sk_state = TCP_CLOSE;
return err;
}
listen(2) の引数である backlog が設定されている。
sk->sk_max_ack_backlog = backlog;
sk->sk_ack_backlog = 0;
試しに nc を strace すると backlog は1となっていることが確認できる。
$ strace nc -lvp 12345
...
bind(3, {sa_family=AF_INET, sin_port=htons(12345), sin_addr=inet_addr("0.0.0.0")}, 16) = 0
listen(3, 1) = 0
write(2, "Listening on [0.0.0.0] (family 0"..., 46Listening on [0.0.0.0] (family 0, port 12345)
) = 46
...
backlog は ss では Send-Q に表示される。
$ ss -tan
LISTEN 0 1 0.0.0.0:12345 0.0.0.0:*
つまり、 sk->sk_max_ack_backlog とは Send-Q のことである。
後述するが、Recv-Q は accept(2) 待ちの現在のキュー(以下 Accept Queue)の数数である。
この backlog が溢れた場合にどのような挙動になるかも、後ほど後述する。
SYN → NEW_SYN_RECV になるまで
TCP(v4)パケットを受け取った際は、 tcp_v4_do_rcv() が呼び出される。
int tcp_v4_do_rcv(struct sock *sk, struct sk_buff *skb)
{
struct sock *rsk;
if (sk->sk_state == TCP_ESTABLISHED) { /* Fast path */
struct dst_entry *dst = sk->sk_rx_dst;
sock_rps_save_rxhash(sk, skb);
sk_mark_napi_id(sk, skb);
if (dst) {
if (inet_sk(sk)->rx_dst_ifindex != skb->skb_iif ||
!dst->ops->check(dst, 0)) {
dst_release(dst);
sk->sk_rx_dst = NULL;
}
}
tcp_rcv_established(sk, skb, tcp_hdr(skb));
return 0;
}
if (tcp_checksum_complete(skb))
goto csum_err;
if (sk->sk_state == TCP_LISTEN) {
struct sock *nsk = tcp_v4_cookie_check(sk, skb);
if (!nsk)
goto discard;
if (nsk != sk) {
if (tcp_child_process(sk, nsk, skb)) {
rsk = nsk;
goto reset;
}
return 0;
}
} else
sock_rps_save_rxhash(sk, skb);
if (tcp_rcv_state_process(sk, skb)) {
rsk = sk;
goto reset;
}
return 0;
...
現在、ソケットは LISTEN なので次の箇所が呼ばれる。
if (sk->sk_state == TCP_LISTEN) {
struct sock *nsk = tcp_v4_cookie_check(sk, skb);
if (!nsk)
goto discard;
if (nsk != sk) {
if (tcp_child_process(sk, nsk, skb)) {
rsk = nsk;
goto reset;
}
return 0;
}
}
tcp_v4_cookie_check() は SYN Cookie 周りの処理。
tcp_child_process() は次のようになっている。
int tcp_child_process(struct sock *parent, struct sock *child,
struct sk_buff *skb)
{
int ret = 0;
int state = child->sk_state;
/* record NAPI ID of child */
sk_mark_napi_id(child, skb);
tcp_segs_in(tcp_sk(child), skb);
if (!sock_owned_by_user(child)) {
ret = tcp_rcv_state_process(child, skb);
/* Wakeup parent, send SIGIO */
if (state == TCP_SYN_RECV && child->sk_state != state)
parent->sk_data_ready(parent);
} else {
/* Alas, it is possible again, because we do lookup
* in main socket hash table and lock on listening
* socket does not protect us more.
*/
__sk_add_backlog(child, skb);
}
bh_unlock_sock(child);
sock_put(child);
return ret;
}
続いて呼ばれるのは tcp_rcv_state_process() だ。
int tcp_rcv_state_process(struct sock *sk, struct sk_buff *skb)
{
struct tcp_sock *tp = tcp_sk(sk);
struct inet_connection_sock *icsk = inet_csk(sk);
const struct tcphdr *th = tcp_hdr(skb);
struct request_sock *req;
int queued = 0;
bool acceptable;
switch (sk->sk_state) {
case TCP_CLOSE:
goto discard;
case TCP_LISTEN:
if (th->ack)
return 1;
if (th->rst)
goto discard;
if (th->syn) {
if (th->fin)
goto discard;
/* It is possible that we process SYN packets from backlog,
* so we need to make sure to disable BH right there.
*/
local_bh_disable();
acceptable = icsk->icsk_af_ops->conn_request(sk, skb) >= 0;
local_bh_enable();
if (!acceptable)
return 1;
consume_skb(skb);
return 0;
}
goto discard;
...
LISTEN の処理を見ていくと conn_request() が呼ばれている。
これは tcp_v4_conn_request() を呼び出している。
さらに tcp_conn_request() を呼び出している。
int tcp_conn_request(struct request_sock_ops *rsk_ops,
const struct tcp_request_sock_ops *af_ops,
struct sock *sk, struct sk_buff *skb)
{
struct tcp_fastopen_cookie foc = { .len = -1 };
__u32 isn = TCP_SKB_CB(skb)->tcp_tw_isn;
...
if ((net->ipv4.sysctl_tcp_syncookies == 2 ||
inet_csk_reqsk_queue_is_full(sk)) && !isn) {
want_cookie = tcp_syn_flood_action(sk, skb, rsk_ops->slab_name);
if (!want_cookie)
goto drop;
}
if (sk_acceptq_is_full(sk)) {
NET_INC_STATS(sock_net(sk), LINUX_MIB_LISTENOVERFLOWS);
goto drop;
}
req = inet_reqsk_alloc(rsk_ops, sk, !want_cookie);
...
if (!want_cookie && !isn) {
/* Kill the following clause, if you dislike this way. */
if (!net->ipv4.sysctl_tcp_syncookies &&
(net->ipv4.sysctl_max_syn_backlog - inet_csk_reqsk_queue_len(sk) <
(net->ipv4.sysctl_max_syn_backlog >> 2)) &&
!tcp_peer_is_proven(req, dst)) {
/* Without syncookies last quarter of
* backlog is filled with destinations,
* proven to be alive.
* It means that we continue to communicate
* to destinations, already remembered
* to the moment of synflood.
*/
pr_drop_req(req, ntohs(tcp_hdr(skb)->source),
rsk_ops->family);
goto drop_and_release;
}
isn = af_ops->init_seq(skb);
}
...
SYN Cookie や fastopen 周りの処理が行われている。
inet_csk_reqsk_queue_is_full() は次のようになっている。
現在のキューが backlog を超過していないかを確認している。
static inline int inet_csk_reqsk_queue_is_full(const struct sock *sk)
{
return inet_csk_reqsk_queue_len(sk) >= sk->sk_max_ack_backlog;
}
ここで net->ipv4.sysctl_tcp_syncookies == 2 や tcp_syn_flood_action() 関数などがでてきたので、そちらも確認しよう。
これは SYN Flood 対策のためのもので、キューが溜まった場合、新規にキューに突っ込むことができずにプロセスと疎通が取れなくなってしまう。
そこで SYN Cookies と呼ばれるものが作られた。それを有効/無効にするのが net.ipv4.tcp_syncookies だ。
tcp_syn_flood_action() は次のようになっている。
static bool tcp_syn_flood_action(const struct sock *sk,
const struct sk_buff *skb,
const char *proto)
{
struct request_sock_queue *queue = &inet_csk(sk)->icsk_accept_queue;
const char *msg = "Dropping request";
bool want_cookie = false;
struct net *net = sock_net(sk);
#ifdef CONFIG_SYN_COOKIES
if (net->ipv4.sysctl_tcp_syncookies) {
msg = "Sending cookies";
want_cookie = true;
__NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPREQQFULLDOCOOKIES);
} else
#endif
__NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPREQQFULLDROP);
if (!queue->synflood_warned &&
net->ipv4.sysctl_tcp_syncookies != 2 &&
xchg(&queue->synflood_warned, 1) == 0)
pr_info("%s: Possible SYN flooding on port %d. %s. Check SNMP counters.\n",
proto, ntohs(tcp_hdr(skb)->dest), msg);
return want_cookie;
}
net.ipv4.tcp_syncookies の値が0の場合はそのまま破棄され、1の場合は syn cookie 付きの SYN/ACK を返している。
というわけで次のことがわかった。
net.ipv4.tcp_syncookies=0のときにキューが一杯だと破棄net.ipv4.tcp_syncookies=1のときは SYN Flood 攻撃と判断し SYN Cookies 付きのパケットを送り返す
tcp_conn_request() に戻る。
if (sk_acceptq_is_full(sk)) {
NET_INC_STATS(sock_net(sk), LINUX_MIB_LISTENOVERFLOWS);
goto drop;
}
キューが一杯のときに LINUX_MIB_LISTENOVERFLOWS がインクリメントされる。
この定義は https://elixir.bootlin.com/linux/v4.15/source/include/uapi/linux/snmp.h#L186 で確認できる。
nstat の意味が理解できて便利。
続いて inet_reqsk_alloc() で TCP_NEW_SYN_RECV に状態が変化する。
struct request_sock *inet_reqsk_alloc(const struct request_sock_ops *ops,
struct sock *sk_listener,
bool attach_listener)
{
struct request_sock *req = reqsk_alloc(ops, sk_listener,
attach_listener);
if (req) {
struct inet_request_sock *ireq = inet_rsk(req);
ireq->ireq_opt = NULL;
#if IS_ENABLED(CONFIG_IPV6)
ireq->pktopts = NULL;
#endif
atomic64_set(&ireq->ir_cookie, 0);
ireq->ireq_state = TCP_NEW_SYN_RECV;
write_pnet(&ireq->ireq_net, sock_net(sk_listener));
ireq->ireq_family = sk_listener->sk_family;
}
return req;
}
最後に send_synack() が呼ばれ、 SYN/ACK が送信されている。
また、 inet_csk_reqsk_queue_add(sk, req, fastopen_sk); でキューに追加されている。
ちなみに drop は次のような処理になっている。
drop:
tcp_listendrop(sk);
return 0;
static inline void tcp_listendrop(const struct sock *sk)
{
atomic_inc(&((struct sock *)sk)->sk_drops);
__NET_INC_STATS(sock_net(sk), LINUX_MIB_LISTENDROPS);
}
LINUX_MIB_LISTENDROPS をインクリメントしている。
NEW_SYN_RECV → になるまで
tcp_v4_rcv() で次のような処理が行われている。
process:
if (sk->sk_state == TCP_TIME_WAIT)
goto do_time_wait;
if (sk->sk_state == TCP_NEW_SYN_RECV) {
struct request_sock *req = inet_reqsk(sk);
struct sock *nsk;
sk = req->rsk_listener;
if (unlikely(tcp_v4_inbound_md5_hash(sk, skb))) {
sk_drops_add(sk, skb);
reqsk_put(req);
goto discard_it;
}
if (unlikely(sk->sk_state != TCP_LISTEN)) {
inet_csk_reqsk_queue_drop_and_put(sk, req);
goto lookup;
}
/* We own a reference on the listener, increase it again
* as we might lose it too soon.
*/
sock_hold(sk);
refcounted = true;
nsk = NULL;
if (!tcp_filter(sk, skb)) {
th = (const struct tcphdr *)skb->data;
iph = ip_hdr(skb);
tcp_v4_fill_cb(skb, iph, th);
nsk = tcp_check_req(sk, skb, req, false);
}
if (!nsk) {
reqsk_put(req);
goto discard_and_relse;
}
if (nsk == sk) {
reqsk_put(req);
tcp_v4_restore_cb(skb);
} else if (tcp_child_process(sk, nsk, skb)) {
tcp_v4_send_reset(nsk, skb);
goto discard_and_relse;
} else {
sock_put(sk);
return 0;
}
}
...
sk->icsk_accept_queue と sk->sk_ack_backlog がある。
icsk_accept_queue は request_sock_queue https://elixir.bootlin.com/linux/v4.15/source/include/net/request_sock.h#L164 ack_backlog は https://elixir.bootlin.com/linux/v4.15/source/include/net/sock.h#L458
static inline bool sk_acceptq_is_full(const struct sock *sk)
{
return sk->sk_ack_backlog > sk->sk_max_ack_backlog;
}
static inline int inet_csk_reqsk_queue_is_full(const struct sock *sk)
{
return inet_csk_reqsk_queue_len(sk) >= sk->sk_max_ack_backlog;
}